Multimodal Integration of Human-Like Attention in Visual Question Answering
Ekta Sood, Fabian Kögel, Philipp Müller, Dominike Thomas, Mihai Bâce, Andreas Bulling
Proc. Workshop on Gaze Estimation and Prediction in the Wild (GAZE), CVPRW, pp. 2647–2657, 2023.
Tobii Sponsor Award, Oral Presentation
Abstract
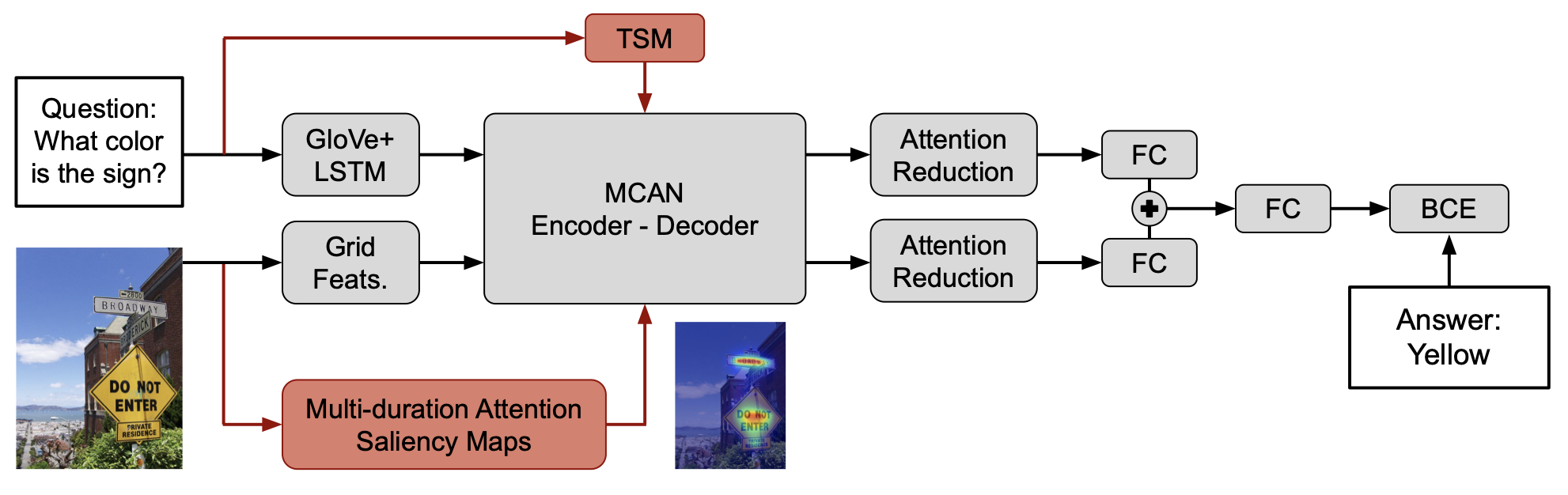
Human-like attention as a supervisory signal to guide neural attention has shown significant promise but is currently limited to uni-modal integration – even for inherently multi-modal tasks such as visual question answering (VQA). We present the Multimodal Human-like Attention Network (MULAN) – the first method for multimodal integration of human-like attention on image and text during training of VQA models. MULAN integrates attention predictions from two state-of-the-art text and image saliency models into neural self-attention layers of a recent transformer-based VQA model. Through evaluations on the challenging VQAv2 dataset, we show that MULAN achieves a new state-of-the-art performance of 73.98% accuracy on test-std and 73.72% on test-dev and, at the same time, has approximately 80% fewer trainable parameters than prior work. Overall, our work underlines the potential of integrating multimodal human-like and neural attention for VQA.Links
BibTeX
@inproceedings{sood23_gaze,
author = {Sood, Ekta and Kögel, Fabian and Müller, Philipp and Thomas, Dominike and Bâce, Mihai and Bulling, Andreas},
title = {Multimodal Integration of Human-Like Attention in Visual Question Answering},
booktitle = {Proc. Workshop on Gaze Estimation and Prediction in the Wild (GAZE), CVPRW},
year = {2023},
pages = {2647--2657},
url = {https://openaccess.thecvf.com/content/CVPR2023W/GAZE/papers/Sood_Multimodal_Integration_of_Human-Like_Attention_in_Visual_Question_Answering_CVPRW_2023_paper.pdf}
}