Seeing with Humans: Gaze-Assisted Neural Image Captioning
Yusuke Sugano, Andreas Bulling
arXiv:1608.05203, pp. 1–8, 2016.
Abstract
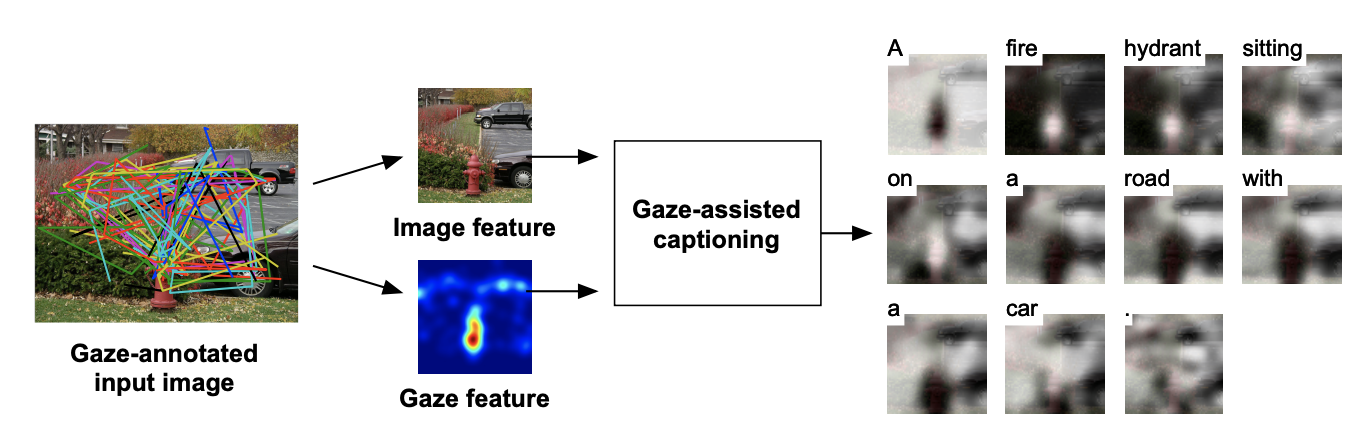
Gaze reflects how humans process visual scenes and is therefore increasingly used in computer vision systems. Previous works demonstrated the potential of gaze for object-centric tasks, such as object localization and recognition, but it remains unclear if gaze can also be beneficial for scene-centric tasks, such as image captioning. We present a new perspective on gaze-assisted image captioning by studying the interplay between human gaze and the attention mechanism of deep neural networks. Using a public large-scale gaze dataset, we first assess the relationship between state-of-the-art object and scene recognition models, bottom-up visual saliency, and human gaze. We then propose a novel split attention model for image captioning. Our model integrates human gaze information into an attention-based long short-term memory architecture, and allows the algorithm to allocate attention selectively to both fixated and non-fixated image regions. Through evaluation on the COCO/SALICON datasets we show that our method improves image captioning performance and that gaze can complement machine attention for semantic scene understanding tasks.Links
Paper: sugano16_tr.pdf
Paper Access: https://arxiv.org/abs/1608.05203
BibTeX
@techreport{sugano16_tr,
title = {Seeing with Humans: Gaze-Assisted Neural Image Captioning},
author = {Sugano, Yusuke and Bulling, Andreas},
year = {2016},
pages = {1--8},
url = {https://arxiv.org/abs/1608.05203}
}