VQA-MHUG: A gaze dataset to study multimodal neural attention in VQA
Ekta Sood, Fabian Kögel, Florian Strohm, Prajit Dhar, Andreas Bulling
Proc. ACL SIGNLL Conference on Computational Natural Language Learning (CoNLL), pp. 27–43, 2021.
Oral Presentation
Abstract
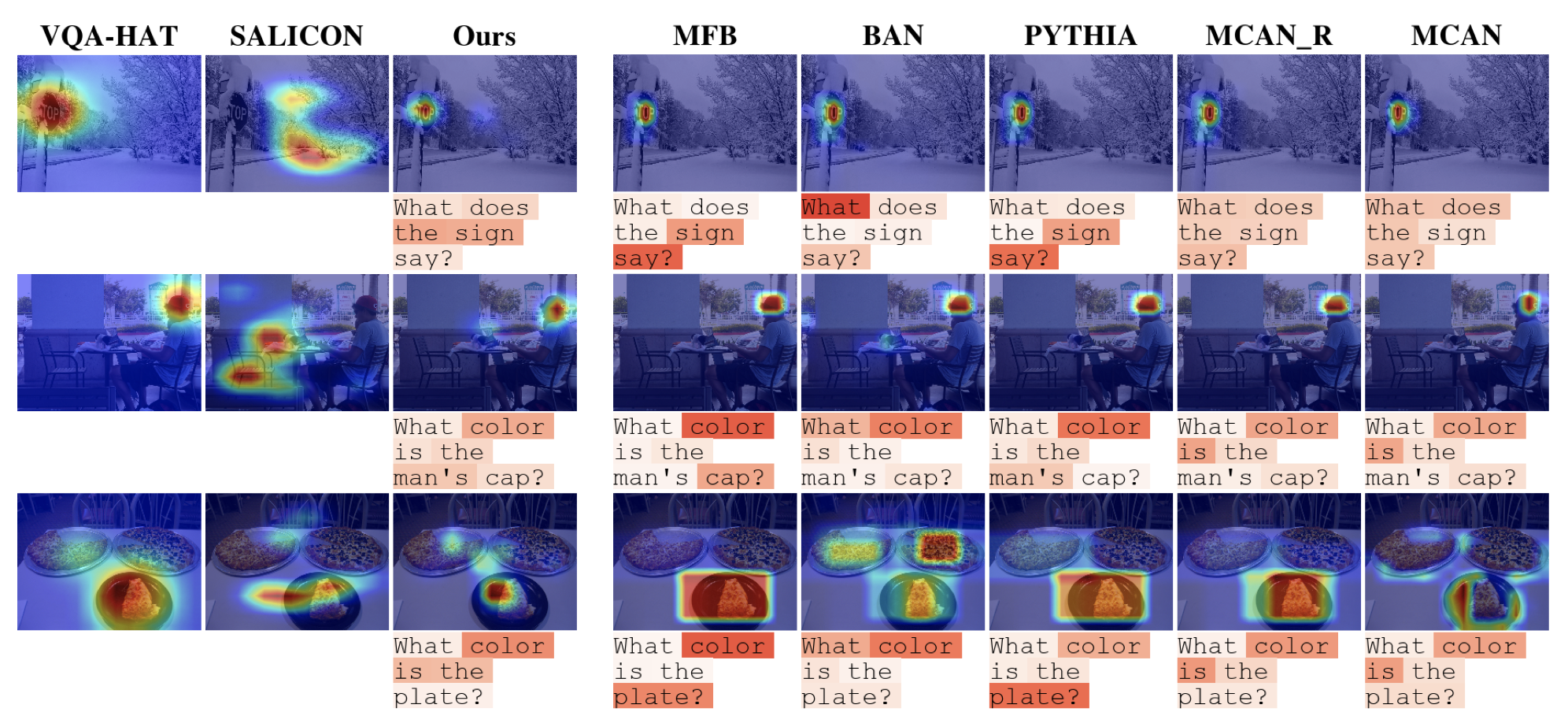
We present VQA-MHUG - a novel 49-participant dataset of multimodal human gaze on both images and questions during visual question answering (VQA) collected using a high-speed eye tracker. We use our dataset to analyze the similarity between human and neural attentive strategies learned by five state-of-the-art VQA models: Modulated Co-Attention Network (MCAN) with either grid or region features, Pythia, Bilinear Attention Network (BAN), and the Multimodal Factorized Bilinear Pooling Network (MFB). While prior work has focused on studying the image modality, our analyses show - for the first time - that for all models, higher correlation with human attention on text is a significant predictor of VQA performance. This finding points at a potential for improving VQA performance and, at the same time, calls for further research on neural text attention mechanisms and their integration into architectures for vision and language tasks, including but potentially also beyond VQA.Links
doi: 10.18653/v1/2021.conll-1.3
Paper: sood21_conll.pdf
Code: https://git.hcics.simtech.uni-stuttgart.de/public-projects/vqa-mhug-interpretability
Dataset: https://collaborative-ai.org/research/datasets/VQA-MHUG/
BibTeX
@inproceedings{sood21_conll,
title = {VQA-MHUG: A gaze dataset to study multimodal neural attention in VQA},
author = {Sood, Ekta and Kögel, Fabian and Strohm, Florian and Dhar, Prajit and Bulling, Andreas},
booktitle = {Proc. ACL SIGNLL Conference on Computational Natural Language Learning (CoNLL)},
year = {2021},
pages = {27--43},
doi = {10.18653/v1/2021.conll-1.3},
publisher = {Association for Computational Linguistics}
}