Multi-Modal Video Dialog State Tracking in the Wild
Adnen Abdessaied, Lei Shi, Andreas Bulling
Proc. 18th European Conference on Computer Vision (ECCV), pp. 1–25, 2024.
Abstract
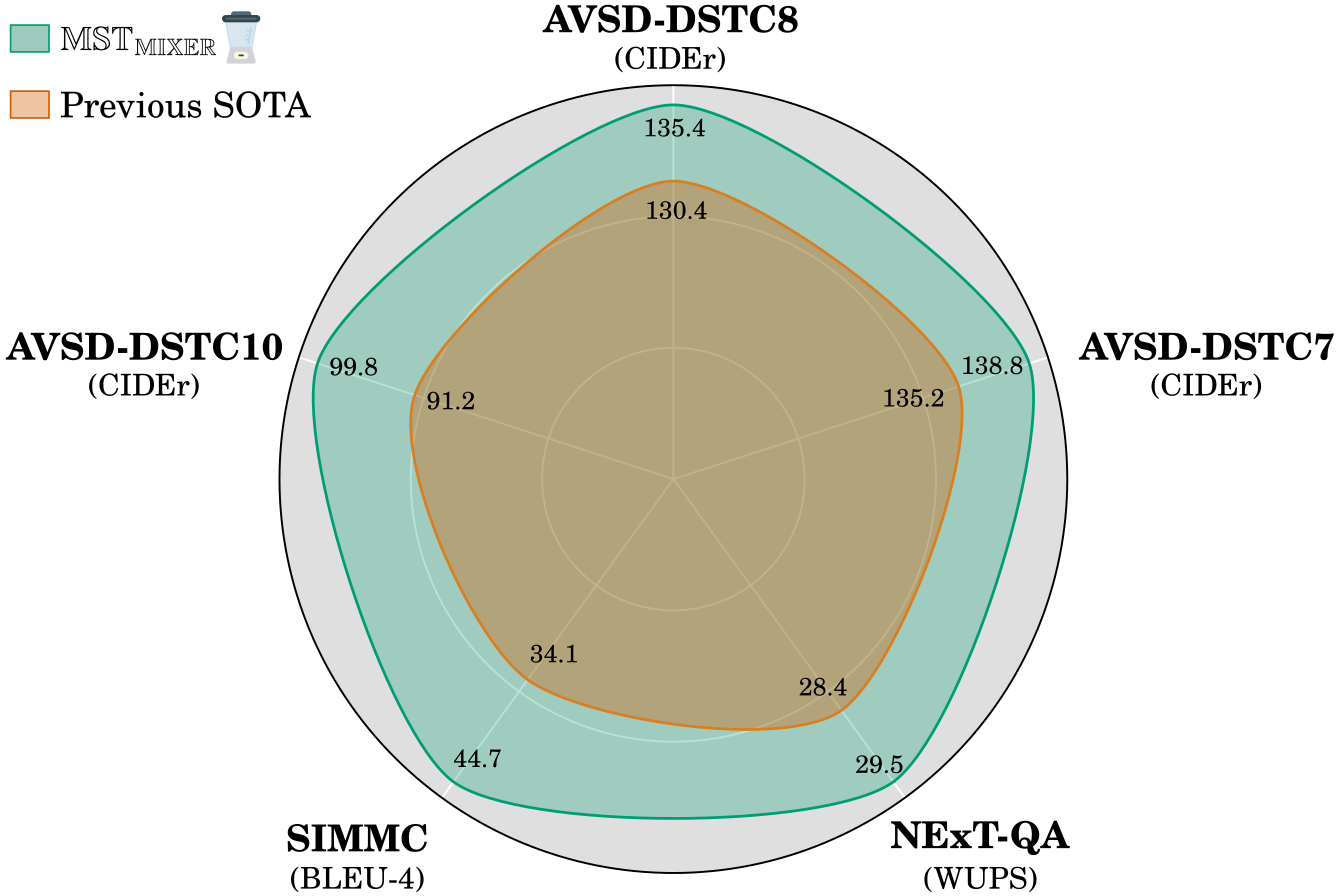
We present MST-MIXER – a novel video dialog model operating over a generic multi-modal state tracking scheme. Current models that claim to perform multi-modal state tracking fall short of two major aspects: (1) They either track only one modality (mostly the visual input) or (2) they target synthetic datasets that do not reflect the complexity of real-world in the wild scenarios. Our model addresses these two limitations in an attempt to close this crucial research gap. Specifically, MST-MIXER first tracks the most important constituents of each input modality. Then, it predicts the missing underlying structure of the selected constituents of each modality by learning local latent graphs using a novel multi-modal graph structure learning method. Subsequently, the learned local graphs and features are parsed together to form a global graph operating on the mix of all modalities which further refines its structure and node embeddings. Finally, the fine-grained graph node features are used to enhance the hidden states of the backbone Vision-Language Model (VLM). MST-MIXER achieves new state-of-the-art results on five challenging benchmarks.Links
doi: 10.1007/978-3-031-72998-0_20
Paper: abdessaied24_eccv.pdf
Code: https://git.hcics.simtech.uni-stuttgart.de/public-projects/MST-MIXER
BibTeX
@inproceedings{abdessaied24_eccv,
author = {Abdessaied, Adnen and Shi, Lei and Bulling, Andreas},
title = {Multi-Modal Video Dialog State Tracking in the Wild},
booktitle = {Proc. 18th European Conference on Computer Vision (ECCV)},
year = {2024},
pages = {1--25},
doi = {10.1007/978-3-031-72998-0_20}
}